

Screaming Frog SEO Spider: Das ultimative Tool für Website-Crawling und SEO-Audits
Technische Suchmaschinenoptimierung steht und fällt mit einer sauberen Website-Struktur. Schon kleine Fehler wie defekte Links, doppelte Inhalte oder fehlende Meta-Daten können Rankings und Sichtbarkeit kosten. Der Screaming Frog SEO Spider analysiert Websites wie ein Suchmaschinen-Crawler und deckt dabei zuverlässig alle relevanten OnPage- und Technikfaktoren auf. Damit zählt er zu den unverzichtbaren Werkzeugen im SEO-Alltag und ist besonders für E-Commerce, Agenturen und Unternehmen mit komplexen Webprojekten essenziell.

Navigation

Julian Gwiasda
Was ist Screaming Frog?
Der Screaming Frog SEO Spider ist eine Desktop-Software für Windows, macOS und Linux. Entwickelt wurde das Tool von der britischen Agentur Screaming Frog Ltd., die seit vielen Jahren auf SEO spezialisiert ist. Heute zählt der Spider zu den bekanntesten und am weitesten verbreiteten Programmen für Website-Crawling. Er simuliert die Funktionsweise eines Suchmaschinen-Bots und prüft dabei sämtliche URLs einer Website. Auf diese Weise lassen sich technische und inhaltliche SEO-Probleme schnell und präzise identifizieren. Ob defekte Links, doppelte Inhalte oder fehlende Meta-Daten: Der Screaming Frog SEO Spider ist in der Lage, Fehler sichtbar zu machen, die das Ranking einer Website in den Suchmaschinen beeinträchtigen können.
Wie arbeitet der SEO Spider unter der Haube?
Die Arbeitsweise des Screaming Frog SEO Spider orientiert sich am Prinzip der Suchmaschinen-Crawler. Das Tool ruft eine Website URL für URL ab, sammelt dabei Informationen über technische Parameter und OnPage-Inhalte und stellt die Daten in einer klar strukturierten Oberfläche dar. So entsteht ein vollständiges Abbild der Website-Struktur. Dadurch können SEOs nachvollziehen, wie Google und andere Suchmaschinen die Seiten erfassen. Auf Basis dieser Daten lassen sich Optimierungspotenziale und technische Probleme erkennen, bevor sie negative Auswirkungen auf die Sichtbarkeit in den Suchmaschinen haben.
Kostenlos vs. Pro Version
Der Screaming Frog SEO Spider ist sowohl als kostenlose Basis-Version als auch in einer lizenzierten Pro-Version verfügbar. Während die Gratis-Variante ideal für kleine Websites und erste Analysen ist, entfaltet das Tool in der Pro-Version sein volles Potenzial. Hier stehen unbegrenzte Crawls, API-Anbindungen, JavaScript-Rendering und viele weitere Profi-Funktionen zur Verfügung. Wer regelmäßig tiefgehende SEO-Audits durchführt, kommt deshalb an der kostenpflichtigen Lizenz kaum vorbei.
| Funktion / Feature | Kostenlose Version | Pro-Version (ca. 245 € / Jahr) |
|---|---|---|
| Max. Anzahl URLs pro Crawl | 500 | Unbegrenzt |
| Meta-Daten-Analyse | ✔ | ✔ |
| Statuscodes & Redirects | ✔ | ✔ |
| Überschriften-Check (H1/H2) | ✔ | ✔ |
| JavaScript-Rendering | ✘ | ✔ |
| API-Integrationen | ✘ | ✔ (Google Analytics, GSC, Ahrefs, etc.) |
| Custom Extraction (XPath/Regex) | ✘ | ✔ |
| Crawl-Vergleich | ✘ | ✔ |
| Automatisierte Crawls | ✘ | ✔ |
| Sitemaps erstellen | ✘ | ✔ (XML- und Bild-Sitemaps) |
| Support & Updates | Basis | Voller Premium-Support |
Installation und erste Schritte mit Screaming Frog
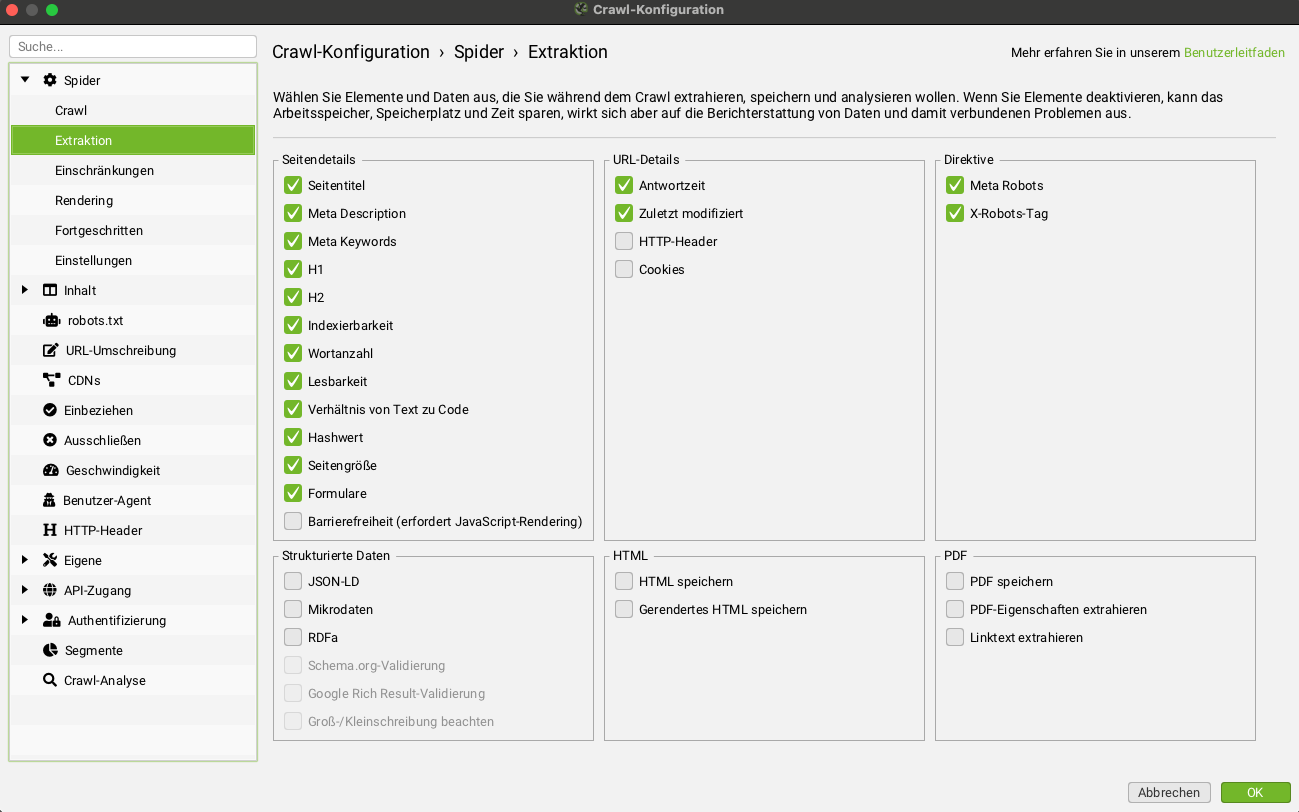
Bevor Screaming Frog seine ganze Stärke entfalten kann, muss das Tool zunächst installiert und eingerichtet werden. Die Installation ist unkompliziert und innerhalb weniger Minuten abgeschlossen. Der SEO Spider ist für Windows, macOS und Linux verfügbar und wird direkt über die offizielle Website von Screaming Frog heruntergeladen. Nach der Installation öffnet sich eine klar strukturierte Benutzeroberfläche, die alle relevanten Funktionen auf einen Blick bereitstellt. Selbst Einsteiger finden sich schnell zurecht und können bereits nach wenigen Klicks den ersten Crawl starten.
Systemvoraussetzungen
Damit Screaming Frog zuverlässig arbeitet, sollte der Rechner über ausreichend Arbeitsspeicher und eine stabile Internetverbindung verfügen. Für kleinere Websites reichen bereits 4 GB RAM aus. Bei sehr großen Crawls, die mehrere hunderttausend URLs umfassen, empfiehlt der Hersteller jedoch mindestens 8 bis 16 GB RAM sowie eine SSD-Festplatte, um die Daten performant zu verarbeiten.
Download und Installation
Die Software kann direkt auf der Website von Screaming Frog heruntergeladen werden. Nach Auswahl des passenden Betriebssystems startet der Installationsassistent, der Schritt für Schritt durch den Prozess führt. Anschließend lässt sich die Anwendung sofort starten. Nutzer der Pro-Version müssen zusätzlich den Lizenzschlüssel eingeben, um den vollen Funktionsumfang freizuschalten.
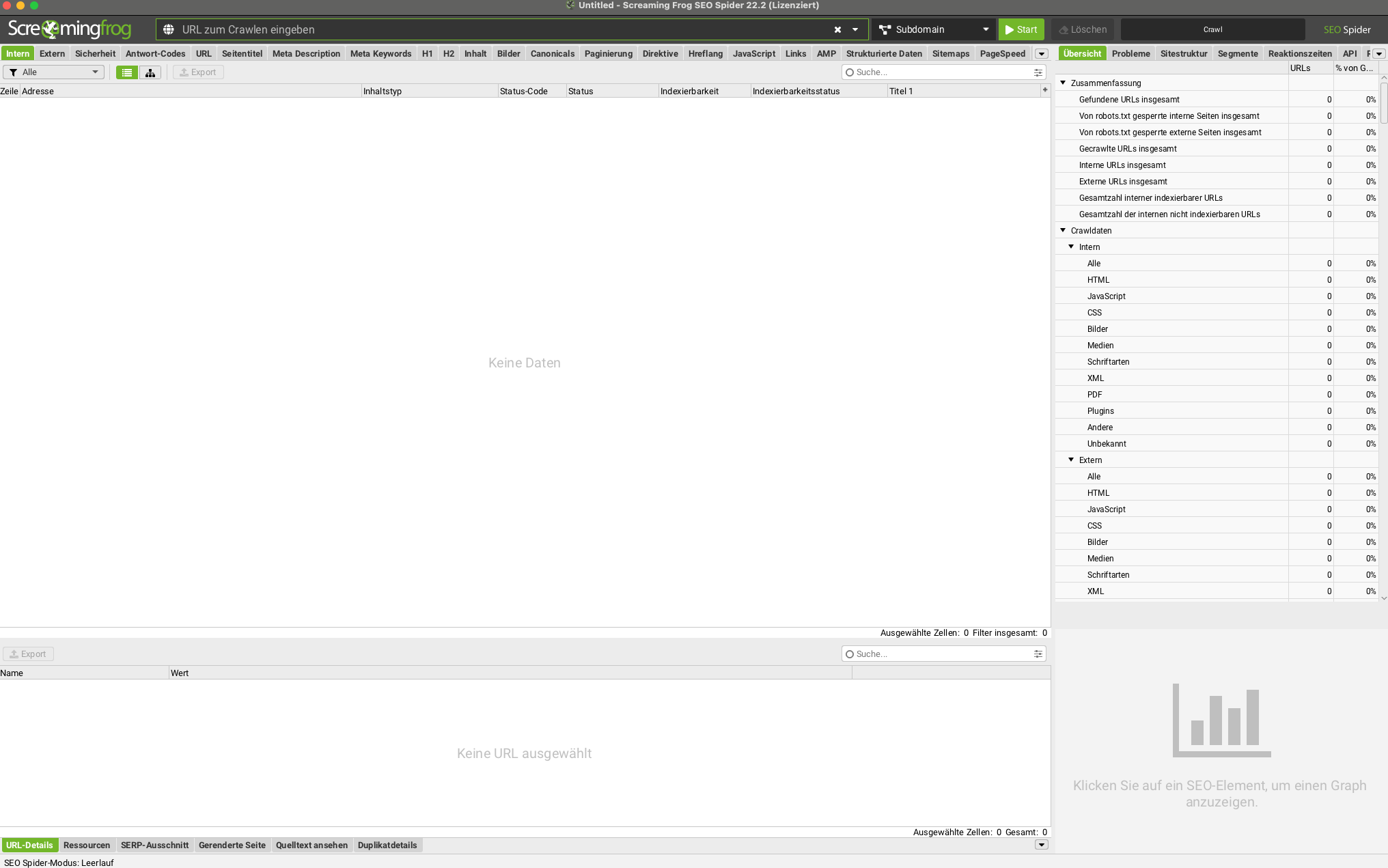
Benutzeroberfläche im Überblick
Die Oberfläche des Screaming Frog SEO Spider ist klar strukturiert und in verschiedene Tabs unterteilt. Im Hauptfenster werden die gecrawlten URLs tabellarisch dargestellt, ergänzt durch Informationen zu Meta-Daten, Statuscodes, Überschriften und vielen weiteren SEO-Faktoren. Über die linke Navigation lassen sich Filter aktivieren, sodass nur bestimmte Inhalte wie Weiterleitungen oder fehlerhafte Seiten angezeigt werden. Am unteren Rand befinden sich zusätzliche Ansichten wie Inlinks, Outlinks oder Ankertexte. So haben Nutzer jederzeit die Möglichkeit, tief in die Analyse einzusteigen.
Crawl-Modi in Screaming Frog
Screaming Frog bietet mehrere Modi, um unterschiedliche Analyseziele effizient abzudecken. Der Standardmodus crawlt komplette Websites, der Listenmodus verarbeitet gezielt vorgegebene URL-Mengen und der Vergleichsmodus stellt zwei Crawls direkt gegenüber. Mit der richtigen Auswahl sparst du Zeit, reduzierst Serverlast und bekommst genau die Daten, die du für die nächste Optimierungsrunde brauchst.
Spider Mode
Der Spider Mode ist der klassische Vollcrawl einer Domain. Er folgt internen Links, wertet Statuscodes und Metadaten aus und bildet die Informationsarchitektur vollständig ab.
Typische Einsatzfälle
- Technisches SEO-Audit einer kompletten Website
- Vorbereitung auf einen Relaunch
- Regelmäßiges Monitoring großer Domains
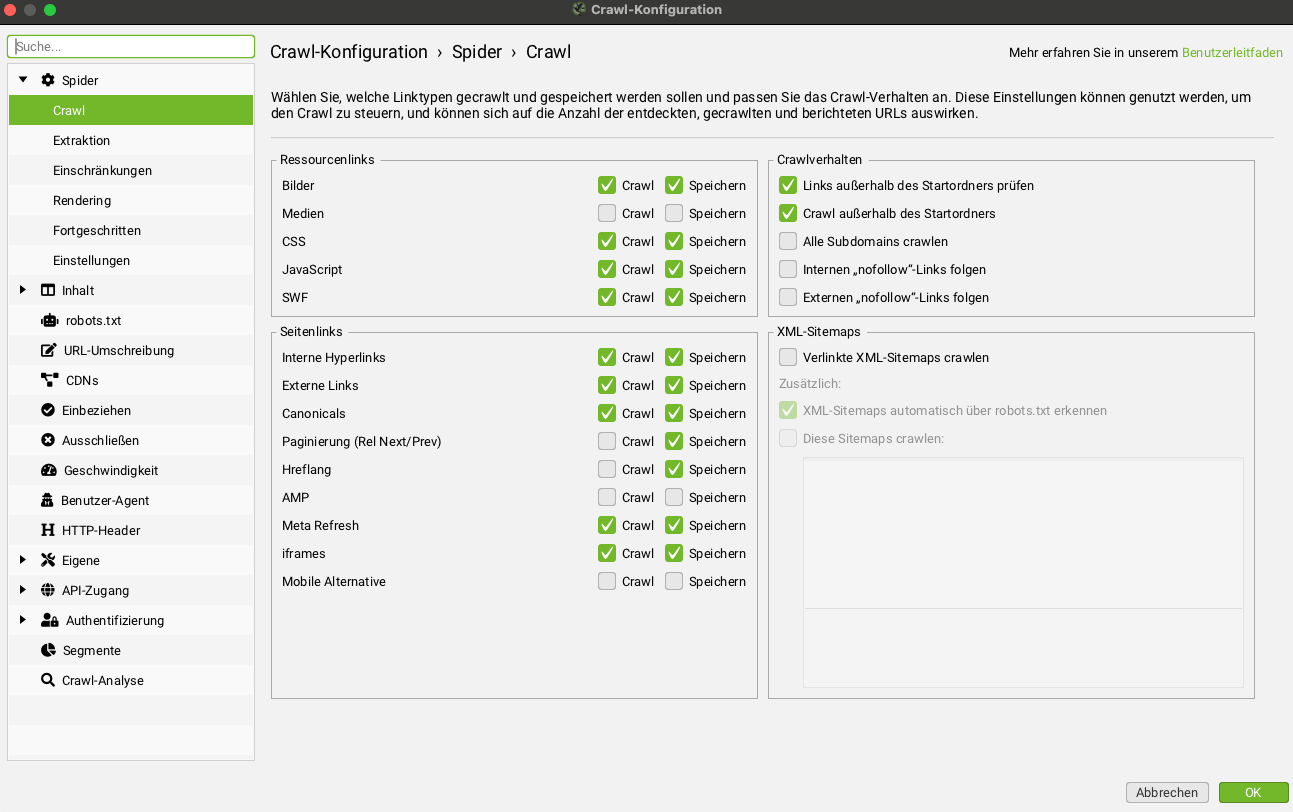
Wichtige Einstellungen
- Start-URL definieren und Protokoll festlegen
- Robots.txt beachten oder ignorieren je nach Zielsetzung
- Subdomains ein- oder ausschließen
- JavaScript-Rendering aktivieren, wenn Inhalte clientseitig geladen werden
- Crawl-Tiefe begrenzen, wenn zunächst nur obere Ebenen analysiert werden sollen
- Externe Links erfassen, aber nicht folgen, um Fokus und Laufzeit zu steuern
Praktische Hinweise
- Für sehr große Seiten den Database Storage Mode verwenden
- Crawl-Pause nutzen, um Serverlast zu reduzieren
- Benutzeragent sinnvoll wählen, etwa Smartphone oder Desktop
- Timeout und Max Redirects anpassen, um Hänger zu vermeiden
List Mode
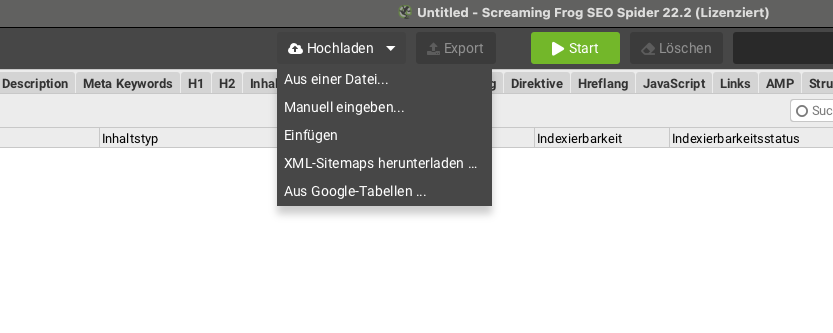
Der List Mode verarbeitet eine definierte URL-Liste, die du aus einer Datei oder der Zwischenablage übergibst. So prüfst du zielgenau nur die Seiten, die wirklich relevant sind.
Typische Einsatzfälle
- Kontrolle wichtiger Templates wie Kategorien, Produktseiten, Ratgeber
- Revalidierung nach Deployments oder Hotfixes
- Prüfung aller Zielseiten aus Kampagnen, Sitemaps oder Backlink-Exports
- Nachkontrolle von Weiterleitungen nach einem Mapping
Ablauf
- URL-Liste importieren als CSV, TXT oder direkt einfügen
- Optional Parameter entfernen lassen, um Dubletten zu vermeiden
- Filter aktivieren, zum Beispiel nur Statuscodes oder nur Metadaten
- Ergebnisse exportieren und an Stakeholder übergeben
Tipps
- URL-Listen aus der Search Console, aus Logfiles oder aus Sitemaps kombinieren
- Bei wiederkehrenden Checks die Liste versionieren
- Mit Custom Extraction zusätzliche Datenpunkte wie Preis, SKU oder Structured Data erfassen
Crawl Comparison
Der Vergleichsmodus stellt zwei Crawls zueinander in Beziehung. Du erkennst dadurch Veränderungen an Statuscodes, Titeln, Canonicals, hreflang, Inlinks und vielen weiteren Feldern.
Typische Einsatzfälle
- Vorher-nachher-Analyse eines Relaunches
- Erkennen schleichender Fehler durch Releases
- Erfolgskontrolle nach Redirect-Mappings
- Überwachung saisonaler Content-Anpassungen
Vorgehen
- Zwei relevante Crawls auswählen oder erneut durchlaufen lassen
- Vergleich starten und Differenzen nach Typ filtern
- Kritische Abweichungen priorisieren, zum Beispiel 200 zu 404, 200 zu 301, Verlust von Indexierbarkeit
- Export der Diffs für Tickets und Dokumentation
Priorisierung
- Statuscode-Änderungen mit Trafficverlustpotenzial
- Verlust von Canonicals oder hreflang
- Rückgang interner Verlinkung und Linktiefe
- Änderungen an Title und Meta Description bei Top-URLs
Konfiguration und Scope-Steuerung
Die Qualität der Ergebnisse hängt stark von der Eingangskonfiguration ab. Mit präzisen Regeln steuerst du, wie tief und breit Screaming Frog crawlt.
Wesentliche Optionen
- Include-Regeln für relevante Pfade wie Kategorien oder Marken
- Exclude-Regeln für Staging, interne Tools, Filterparameter
- Parameterbehandlung, um Facetten und Tracking zu kontrollieren
- Geschwindigkeit über gleichzeitige Verbindungen und Verzögerung regulieren
- Sitemap als Startquelle verwenden, wenn du nur indexrelevante Seiten prüfen willst
JavaScript-Rendering
Immer mehr Websites setzen auf moderne Frameworks wie React, Angular oder Vue. Diese liefern Inhalte nicht mehr vollständig statisch aus, sondern laden sie erst im Browser nach. Klassische Crawler stoßen dabei schnell an Grenzen, da sie ohne Rendering nur die Grundstruktur erkennen und viele Inhalte übersehen würden.
Der Screaming Frog SEO Spider löst dieses Problem durch eine integrierte Rendering-Engine. Damit stellt er Seiten so dar, wie sie auch für echte Nutzer sichtbar sind. Dynamisch nachgeladene Inhalte, Navigationselemente oder Produktinformationen werden zuverlässig erfasst und in den Crawl-Daten abgebildet.
Für SEO-Analysen bedeutet das: Alle relevanten Inhalte werden berücksichtigt. Wichtige Informationen gehen nicht verloren, und die Daten zeigen ein realistisches Bild davon, wie Suchmaschinen die Seite wahrnehmen.
Allerdings ist zu beachten, dass JavaScript-Rendering mehr Rechenleistung benötigt und Crawls dadurch länger dauern. Gerade bei großen Websites mit vielen tausend Unterseiten kann das die Analyse spürbar verlangsamen.
Trotzdem ist diese Funktion unverzichtbar, vor allem bei E-Commerce-Seiten oder Single-Page-Applications. Nur so lassen sich technische Schwachstellen und Optimierungspotenziale in vollem Umfang erkennen.
Datenquellen verbinden
Der Screaming Frog SEO Spider lässt sich mit wichtigen Tools verknüpfen, um Crawl-Daten mit Leistungskennzahlen anzureichern.
Über Google Analytics werden Besucherdaten sichtbar. So lässt sich schnell erkennen, welche Seiten Traffic haben und welche trotz sauberer Struktur kaum Nutzer erreichen.
Mit der Google Search Console erhält man zusätzlich Klicks, Impressionen und Ranking-Positionen. Das macht es einfacher, Seiten mit Potenzial zu identifizieren und gezielt zu optimieren.
Durch die Integration von PageSpeed Insights können Ladezeiten direkt im Crawl bewertet werden – inklusive echter Felddaten aus dem Chrome User Experience Report.
Auch Backlink-Daten aus Ahrefs, Moz oder Majestic können eingebunden werden. Dadurch zeigt sich, welche URLs besonders wichtig für die interne Verlinkung sind.
Die Verknüpfung externer Quellen sorgt dafür, dass technische Analysen mit echten Leistungsdaten kombiniert werden. Das macht Entscheidungen im SEO-Alltag deutlich fundierter.

Export und Zusammenarbeit
Die Daten, die Screaming Frog sammelt, lassen sich vielseitig weiterverwenden und erleichtern die Zusammenarbeit im Team. Ergebnisse können in Excel- oder CSV-Dateien exportiert und für Reports oder Detailanalysen genutzt werden. Für große Projekte stehen Bulk-Exporte zur Verfügung, mit denen sich gezielt bestimmte Fehlerarten wie Weiterleitungen oder 404-Seiten herausfiltern lassen. Darüber hinaus ermöglicht die API-Anbindung eine direkte Integration in Business-Intelligence-Systeme oder Dashboards, sodass die Daten automatisch in bestehende Workflows einfließen. Auf diese Weise können SEO-Analysen effizient an Entwickler, Content-Manager und andere Projektbeteiligte weitergegeben und schnell in konkrete Maßnahmen umgesetzt werden.
Qualitätssicherung vor dem Crawl
Damit ein Crawl zuverlässige Ergebnisse liefert, ist eine kurze Vorbereitung entscheidend. Zuerst sollte die richtige Start-URL gewählt werden, inklusive Protokoll und Subdomain. Danach gilt es festzulegen, ob robots.txt-Regeln berücksichtigt werden sollen oder nicht. Über Include- und Exclude-Filter lässt sich der Crawl gezielt auf relevante Bereiche eingrenzen. Wer JavaScript-Rendering nutzt, aktiviert es am besten nur dort, wo es notwendig ist, um Zeit und Ressourcen zu sparen. Auch die Crawl-Geschwindigkeit sollte an die Serverleistung angepasst werden. Mit diesen wenigen Einstellungen wird sichergestellt, dass der Crawl reibungslos läuft und präzise Daten liefert.
Zentrale Features im Detail
OnPage-Analyse
Screaming Frog prüft Titel, Meta-Descriptions und Überschriften und zeigt Fehler wie fehlende, zu lange oder doppelte Angaben. Auch Bilder werden erfasst, fehlende ALT-Texte markiert und große Dateien sichtbar gemacht. Duplicate Content wird zuverlässig erkannt, in neueren Versionen auch semantisch, wodurch Überschneidungen inhaltlich ähnlicher Seiten identifiziert werden können.
Technische SEO
Neben Statuscodes und Weiterleitungen analysiert das Tool auch Canonical-Tags, hreflang-Implementierungen und Robots-Anweisungen. So wird sichtbar, ob Suchmaschinen die richtige Seitenversion indexieren. Zudem liefert Screaming Frog wertvolle Einblicke in die interne Verlinkung und deckt isolierte Seiten ohne interne Links auf.
Content und Performance
Mit der Analyse der Wortanzahl zeigt das Tool Thin Content auf. Über die Anbindung an PageSpeed Insights lassen sich Ladezeiten direkt im Crawl prüfen. Dank JavaScript-Rendering können auch moderne Frameworks wie React oder Angular zuverlässig analysiert werden.
Visualisierung und Reporting
Ergebnisse lassen sich nicht nur tabellarisch, sondern auch grafisch darstellen. Der Crawl Tree Graph und die Directory Tree Map visualisieren die Website-Struktur und helfen, komplexe Zusammenhänge auf einen Blick zu erkennen. Exporte in Excel, CSV oder Bulk-Reports machen die Zusammenarbeit im Team besonders effizient.
Erweiterte Funktionen und KI-Integration
Mit der Custom Extraction können individuelle Daten wie Preise oder IDs per XPath oder Regex ausgelesen werden. Externe Quellen wie Google Analytics, die Search Console oder Ahrefs lassen sich einbinden, um Crawl-Daten mit Traffic- und Backlink-Informationen anzureichern. Seit Version 21 sind zudem KI-Prompts möglich, mit denen Inhalte automatisiert bewertet werden können. Version 22 ergänzt eine semantische Duplicate-Analyse, die thematisch ähnliche Inhalte erkennt und Content-Strategien präziser macht.
Tipps und Best Practices
Vor jedem Crawl sollten die richtigen Einstellungen gewählt werden. Include- und Exclude-Regeln helfen, den Fokus zu setzen. Für große Projekte ist der Database Storage Mode sinnvoll. JavaScript-Rendering sollte gezielt nur eingesetzt werden, wo es gebraucht wird, um Crawls effizient zu halten. Regelmäßige Analysen stellen sicher, dass technische Fehler schnell entdeckt werden.
Fazit: Lohnt sich Screaming Frog?
Der Screaming Frog SEO Spider ist eines der leistungsfähigsten Tools für technische Suchmaschinenoptimierung. Er kombiniert Crawling, Reporting und KI-gestützte Analysen in einer flexiblen Software, die sowohl für kleine als auch für große Websites geeignet ist. Für Agenturen, Unternehmen und Inhouse-SEOs ist er ein unverzichtbares Werkzeug, um Websites technisch sauber und langfristig erfolgreich zu betreiben.
Wer tiefer einsteigen möchte, findet auf der offiziellen Website von Screaming Frog zahlreiche Ressourcen, Downloads und Dokumentationen. Besonders empfehlenswert ist außerdem der YouTube-Kanal von Screaming Frog, auf dem regelmäßig Tutorials, Anwendungsbeispiele und neue Features vorgestellt werden.
Unsere neusten Blogartikel










Für SEO & SEA
Ihr Ansprechpartner